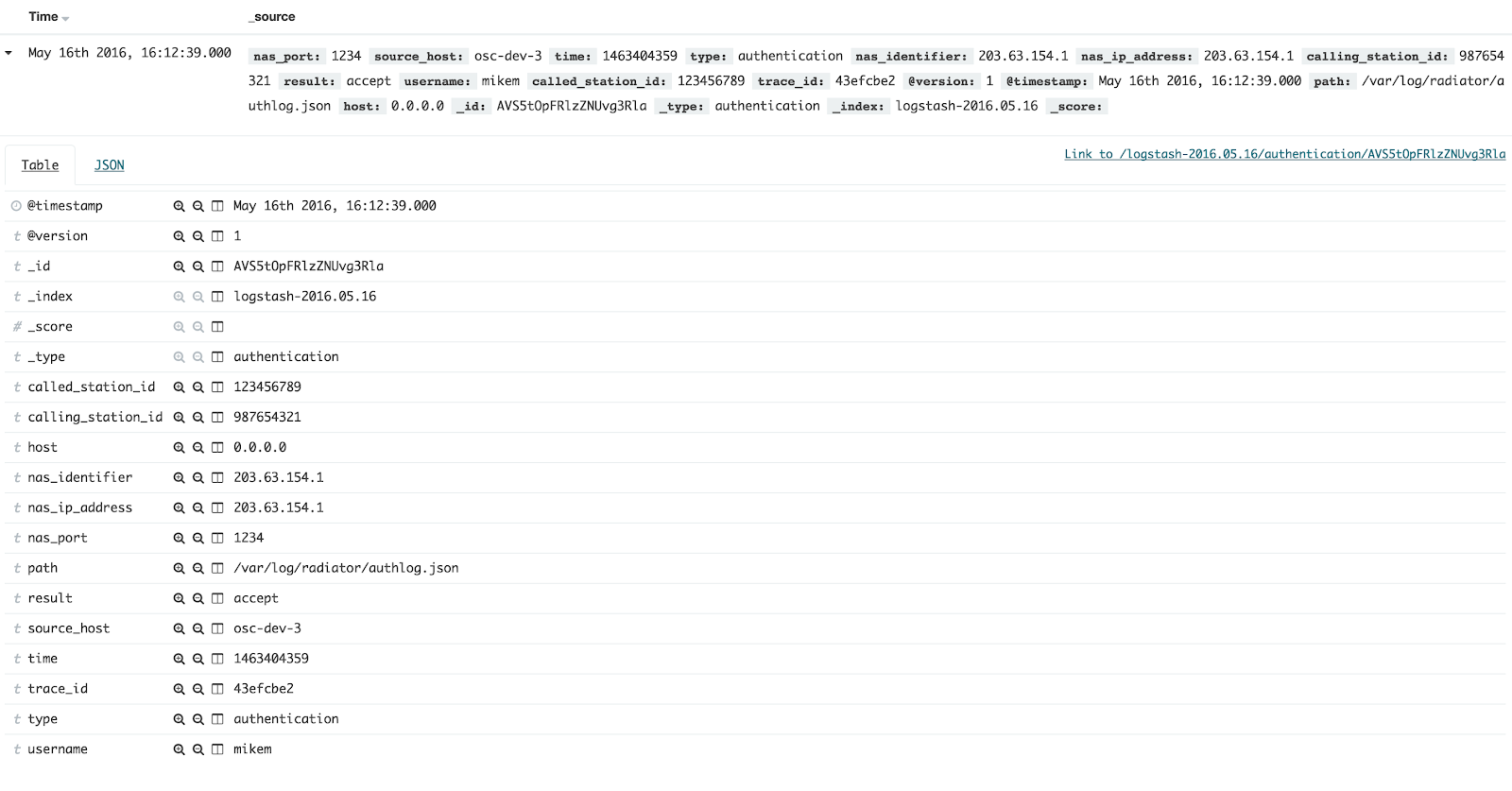
With the first release of the Radiator VNF coming this year, it is a good time to take a quick look at the DevOps model, how we have embraced it, and how it will be on the center of the stage in Radiator VNF.
This post tells you a bit about DevOps in general and an example of a Chef cookbook follows after it. Radiator VNF's configuration management will be discussed in later blog posts.
What is DevOps?
You get multiple different answers when searching for clues behind the portmanteau: DevOps. Sure, it's a merging of
development and
operation
s. Possibly, it's
also a bunch of different tools. Or, you might describe it as a change in the processes of an organisation.
Combining all these, DevOps can be described as a cultural change in the organisation. It's not something you purchase from the store and sprinkle on top of your employees.
DevOps emphasises communication between different parts of the organisation and pushes the processes to be more automated and agile. Changes to the software or configuration are planned, made, tested, deployed, and monitored in a continuous, automated way.
Compared to the old way of divided silos and huge, rarely-made releases with massive change logs, this model encourages making smaller changes, testing them swiftly, and deploying often. Stronger collaboration between developers and operators and a faster, automated cycle improve reliability.
Especially in a flexible and distributed cloud environment, this new approach is needed. Otherwise, it is very difficult for a single operator to manually handle thousands of nodes. The tools grant you the possibility of easily having identical environments with slightly different parameters. With automation, there's no more forgetting to run that command and changing those addresses when manually moving from testing to QA to production.
For us, the shift to a DevOps culture in the customer base means that we also support the DevOps tooling and make it easier for our customers to deploy Radiator with automated configuration management systems. In the Radiator VNF, the whole infrastructure is managed automatically.
Chef, tool for DevOps
Chef is a set of tools developed by a company with the same name. There are several similar tools available, such as
Ansible,
Puppet and
SaltStack among others, so you will find suitable a DevOps-tool for your particular use case.
Chef uses Ruby to describe the infrastructure as code. This means that the configuration of the infrastructure, from the operating system level to the running software services, and their configuration, can be written as Ruby code and then tested like any piece of software.
In Chef terms, the user writes cookbooks which consist of recipes. For example, a cookbook describes a software with different recipes for installation, configuration, and starting the services. The power lies in the community that has written thousands of cookbooks for various tasks. For example, you don't have to write your own cookbooks to install nginx and configure a website. Just download ready-made cookbooks like
chef_nginx and configure them to suite your needs.
By using cookbooks, you can describe your whole infrastructure. The cookbooks can be
unit tested,
integration tested, and after deployment you can ensure
compliance with rules of your organisation.
Short Chef example
As an example and sneak peek for the next post on this theme, here is a quick introduction on Chef cookbooks. These snippets are not complete, but show some features that are used to describe installing Radiator, creating some necessary directories, and starting the service.
If you want a longer introduction on Chef attributes, recipes, and resources, have a look at the
tutorials.
name 'radiator'
maintainer 'Arch Red Oy'
version '0.6.2'
depends 'perl', '~> 4.0.0'
depends 'poise-service', '~> 1.4.1'
supports 'ubuntu', '= 16.04'
supports 'centos', '= 7.2'
default['radiator']['install']['version'] = '4.17'
default['radiator']['install']['method'] = 'archive'
default['radiator']['install']['directory'] = '/opt/radiator'
install_method = node['radiator']['install']['method']
poise_service_user 'radiator' do
group 'radiator'
home node['radiator']['user_home'] unless node['radiator']['user_home'].nil?
shell node['radiator']['user_shell'] unless node['radiator']['user_shell'].nil?
end
%w(/var/run/radiator /var/log/radiator).each do |dir|
directory dir do
owner 'radiator'
group 'radiator'
end
end
unless install_method.nil? || install_method == 'skip'
include_recipe "radiator::install_#{install_method}"
end
case install_method
when 'package'
radiusd_bin = '/usr/bin/radiusd'
dictionary_files << '/etc/radiator/dictionary'
when 'archive', 'evaluation'
radiusd_bin = '/usr/local/bin/radiusd'
radiusd_includes << node['radiator']['install']['directory']
dictionary_files << node['radiator']['install']['directory'] + '/dictionary'
end
unless node['radiator']['options']['dictionary_source'].empty?
dictionary_files << '/etc/radiator/' + node['radiator']['options']['dictionary_file']
end
radiusd_params = ['-foreground', '-config_file /etc/radiator/' + node['radiator']['options']['config_file'],
'-dictionary ' + dictionary_files.flatten.join(','),
node['radiator']['options']['radiusd_params']]
radiusd_includes = [node['radiator']['options']['radiusd_includes'], radiusd_includes].flatten.map { |inc| "-I #{inc}" }
perl_bin = '/usr/bin/env perl'
radiusd_command = [perl_bin, radiusd_includes, radiusd_bin, radiusd_params].flatten.join(' ')
poise_service 'radiator' do
command radiusd_command
user 'radiator'
directory '/etc/radiator'
subscribes :restart, "template[/etc/radiator/#{node['radiator']['options']['config_file']}]"
end